
Wenn über Datenqualität gesprochen wird, fällt schnell der Begriff „Smart Data“. Was Datenqualität mit Smart Data zu tun hat, erfährst du in diesem Beitrag.
Smart Data beschreibt qualitativ hochwertige Daten, auf Basis derer fundierte Geschäftsentscheidungen getroffen werden können. Dabei werden die Daten oftmals mittels intelligenter Algorithmen extrahiert. Aus Smart Data lassen sich Handlungsempfehlungen ableiten und bessere Entscheidungen treffen. Um Smart Data zu erhalten, müssen zwei Hauptherausforderungen von Daten heutzutage adressiert werden:
- verstreute Daten durch Datensilos
- unzureichende Datenqualität
Smarte Daten sind vollständig, richtig, konsolidiert, zusammengeführt, bereinigt und relevant. Smarte Daten filtern die relevanten Informationen und gewährleisten eine hohe Datenqualität.
Wie werden meine Daten denn nun smart?
Exkurs: Dimensionen von Datenqualität
Datenqualität lässt sich in 7 Dimensionen unterteilen. Wir erklären folgend jede Dimension im Einzelnen, um sie anschließend zu Smart Data und den Herausforderungen von Smart Data zu linken.
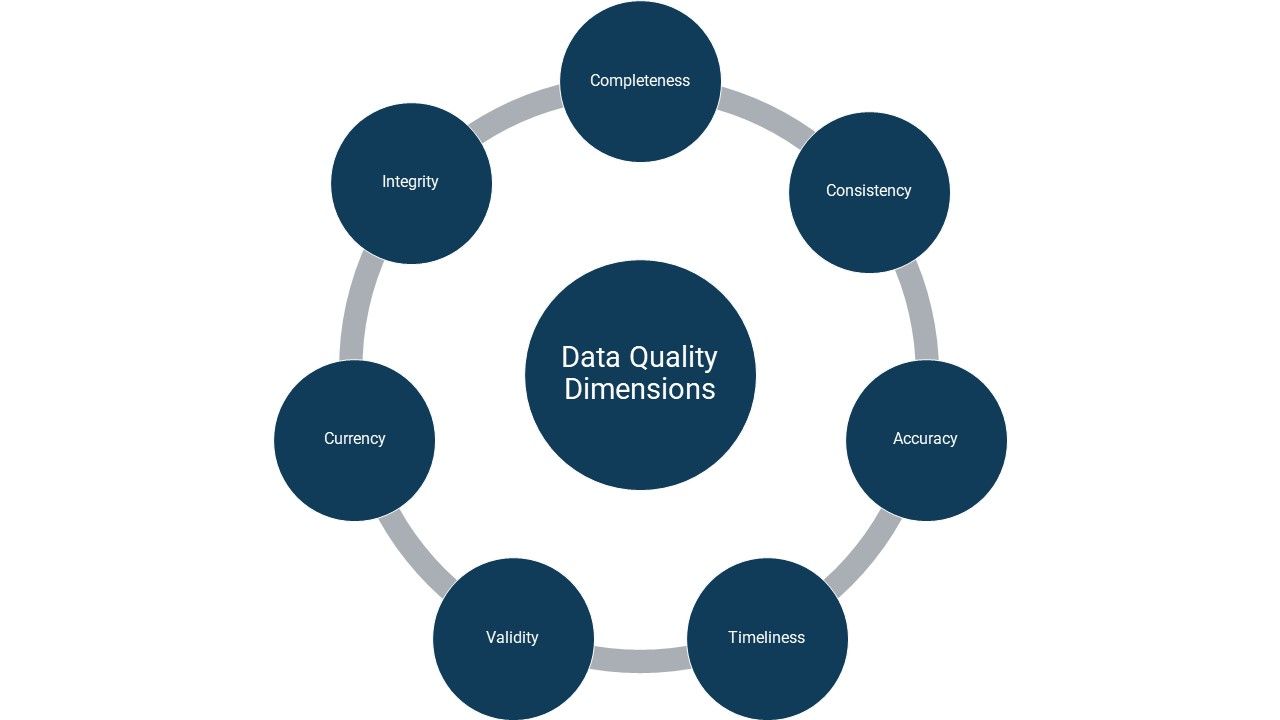
Completeness
Completeness beschreibt, ob die notwendigen Daten vollständig und zugänglich sind. Vollständigkeit kann durch zwei Zustände gemindert werden. Einerseits können zusätzliche Daten nicht zugänglich sein, z.B. in anderen Systemen. Andererseits können diese schlicht unbekannt sein, wie z.B. die Adresse eines Kontakts.
Consistency
Consistency beschreibt, ob deine Daten in unterschiedlichen Systemen gleich vorliegen. Der Grad der Consistency wird dabei daran gemessen, wie unterschiedlich zwei Datensätze, die sich auf das gleiche Objekt (z.B. Person oder Firma) in der realen Welt beziehen, sind.
Accuracy
Accuracy beschreibt, wie korrekt und genau Daten sind. Das kann graduell variieren. Dabei muss es nicht immer eine binäre Entscheidung sein, ob Daten falsch oder richtig sind. So könnte ein Datensatz eigentlich zwei Abteilungen zugeordnet sein. Nehmen wir an, er wäre im entsprechenden System aber nur einer Abteilung zugeordnet. Damit wäre der Datensatz einerseits unvollständig. Andererseits wäre der Datensatz weder gänzlich falsch noch richtig, sondern ungenau. Dies wäre ein Beispiel für den Grad der Genauigkeit.
Timeliness
Timeliness misst die Zeitspanne zwischen den Zeitpunkten, wann Daten erwartet werden gegenüber, wann sie tatsächlich verfügbar sind. Beispielsweise könnten bei einer komplexen Datenbankabfrage die Ergebnisse direkt erwartet werden, jedoch aufgrund der Komplexität und Größe der Datenbank erst nach mehreren Minuten verfügbar sein.
Validity
Validity definiert, ob die Daten im erwarteten bzw. festgelegten Format vorliegen. Zum Beispiel könnte es zwei Felder für die Straße und Hausnummer geben. Wären jetzt bei einem Datensatz die Straße und Hausnummer in einem Feld, wäre das Datum (Singular zu Daten) des Feldes nicht valide.
Currency
Currency beschreibt die Aktualität der Daten. So könnte eine Adresse eines Kunden nicht mehr aktuell sein, weil dieser z.B. umgezogen ist.
Integrity
Integrity misst die Validität und Richtigkeit der Relationen und Beziehungen von Daten untereinander. So können fehlende oder falsche Relationen die Integrity untergraben bzw. mindern.
Wie werden meine Daten smart?
Als erstes musst du deine Datensilos auflösen. Dafür eignet sich eine iPaas-Lösung wie die HubEngine. Halte deine Daten synchron oder sammle, transformiere und route die relevanten Daten an einem Ort wie der DataEngine.
Die Auflösung von Datensilos ist nicht nur aufgrund der Integration eine Herausforderung. Ebenso liegen Daten oftmals in mehreren Systemen vor. Gibt es keinen gemeinsamen Identifier – im Master Data Management nennt sich dies Persistent Identifier (PID) – so ist ein Matching oftmal schwierig. Für diese Problematik werden Machine-Learning-Verfahren für Duplikat-Erkennung („Record Linkage“) eingesetzt. So bildest du keine Duplikate und deine Daten sind sowohl vollständiger als auch richtiger.
Integration löst nicht nur Datensilos auf, sondern erhöht auch deine Datenqualität.
Durch eine saubere Integration – z.B. mit der HubEngine – werden deine Daten primär vollständiger (Completeness) und konsistenter (Consistency). Die anderen Dimensionen werden sekundär ebenfalls positiv beeinflusst. So können Daten schneller verfügbar (Timeliness) sein, wenn du sie zusammenführst. Es müssen nicht mehr unterschiedliche Datenquellen zusammengezogen werden. Weiterhin können Daten valider (Validity) sein, indem du z.B. in der DataEngine Formate definierst oder Daten in der DataEngine über Dun & Bradstreet validierst.
Neben dem Auflösen von Datensilos durch eine saubere iPaas-Lösung wie beispielsweise die HubEngine, ist es ebenso von enormer Wichtigkeit, die Datenqualität zu erhöhen. Dafür sollten die verschiedenen Dimensionen der Datenqualität betrachtet werden. Jede einzelne Dimension lässt sich durch eine Vielfalt an technischen und nicht-technischen Maßnahmen erhöhen. Hier zählen wir für jede Dimension ein Beispiel auf, wie du mit der HubEngine oder DataEngine durch Automatisierung deine Datenqualität erhöhen kannst.
- Completeness: Integration deiner Systeme mit der HubEngine
- Consistency: Integration deiner Systeme mit der HubEngine
- Validity: Nutze Workflows in der DataEngine zum Transformieren der Daten oder Aktionen in der HubEngine, um Formate zu forcieren
- Accuracy: Integration deiner Systeme mit der HubEngine oder Validierung mit Dun & Bradstreet
- Integrity: Bilde alle relevanten Relationen und Beziehungen in der DataEngine bequem und standardmäßig ab
- Timeliness: Verknüpfe und transformiere die relevanten Daten in der DataEngine, sodass du diese dort (oder synchronisiert in deinen anderen Systemen) schnell abrufen kannst
- Currency: Aktualisiere die Daten deiner Firmenkontakte automatisiert mit Dun & Bradstreet
Was mache ich mit meinen Daten, wenn sie smart sind?
Das Ziel von Smart Data ist es, dass du die Bedürfnisse deiner Kunden besser verstehen kannst und somit deren Nachfrage gezielter bedienen kannst. Du triffst bessere Marketing- und Vertriebsentscheidungen und steigerst deinen wirtschaftlichen Erfolg.
Wie du die Daten genau einsetzt – das ist von deinen Geschäftsprozessen abhängig. Du hast nun aber die Grundlage, um deine Prozesse fundiert zu gestalten und zu steuern sowie aus deinen Daten sinnvolle Handlungsempfehlungen abzuleiten.
Ergänzenswert
Um Smart Data zu erhalten, müssen nicht immer Big Data oder unzählige Datenquellen vorliegen. Auch wenige unvollständige und/oder qualitativ unzureichende Daten aus wenigen Quellen können zu Smart Data werden.


