The Relation Store in the HubEngine contains the relations associated with the plan. You can manage the relations by opening a plan and selecting the “Relations” tab. How to manage the relations you will learn in this tutorial.
This post explains in which cases the Relation Store is activated or deactivated. If you don’t know what a HubEngine Relation is, please read the above linked article before. This post requires an understanding of the definition of a HubEngine Relation.
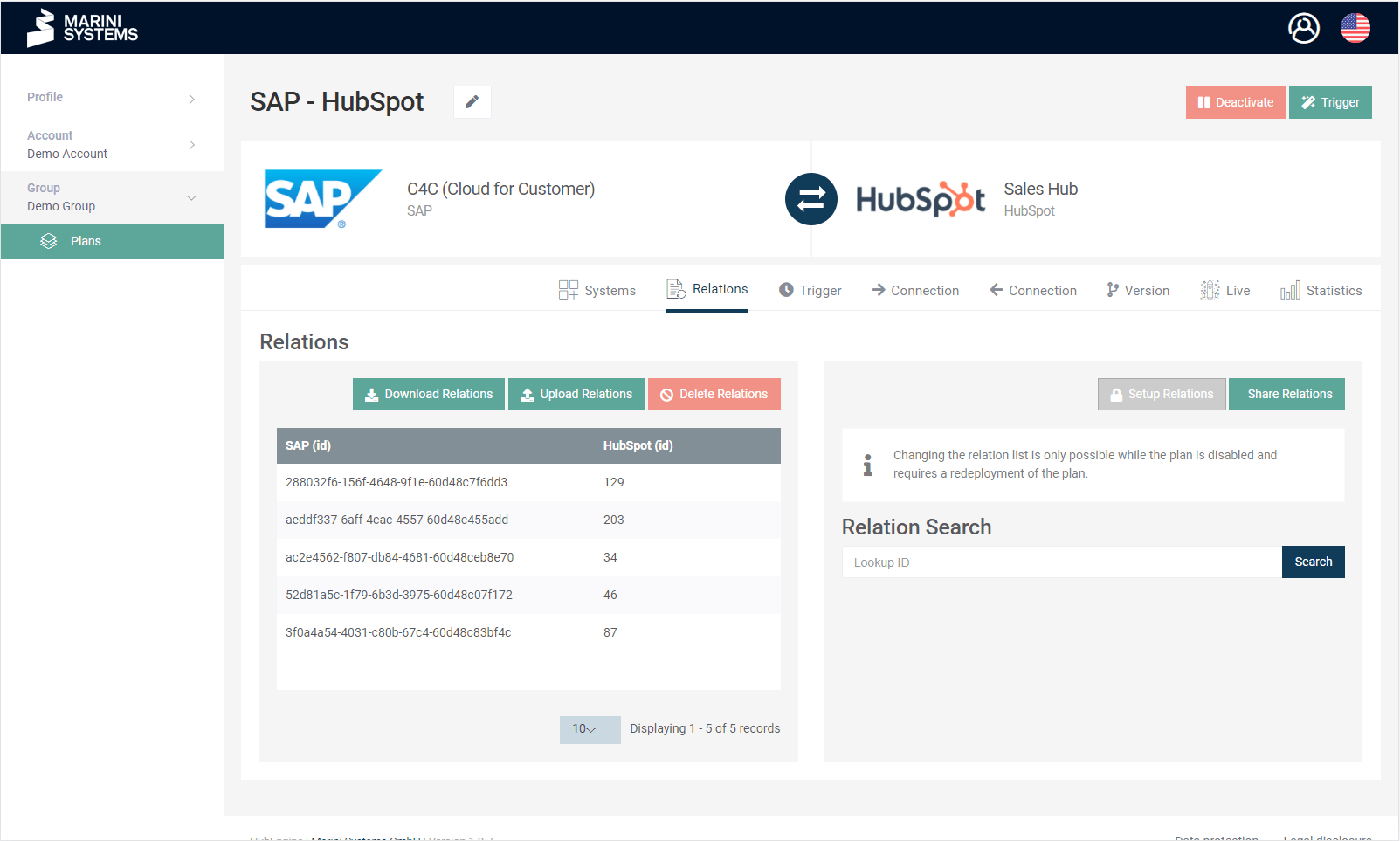
Relation Store activated
The Relation Store can be activated or deactivated at the beginning when configuring up a plan. To explain how the Relation Store works, we differentiate between two cases when the Relation Store is activated.
Case 1: NO records referring to the same object in the real world possible before first synchronization in both systems
We synchronize contact data, uni- or bidirectionally does not matter yet, from system A to system B. The important assumption here is that there can be NO records in both systems that refer to the same object in the real world, in our case to the same person. In other words, there is no record in both systems that describes the same person, e.g. Jane Doe.
We assume that the unique identifier in the systems is the “ID” field, not the email address! Thus, during synchronization, we set the “ID” field as the identifier for system A and B respectively. The initial situation in the systems is as follows:
System A
| ID | Name | |
|---|---|---|
| 1 | john@info.com | John |
| 2 | jane@info.com | Jane |
| 3 | thomas@info.com | Thomas |
System B
| ID | Name | |
|---|---|---|
| A | mary@info.com | Mary |
Important: If we now synchronize based on the ID, we create all records from system A in system B and vice versa!
But this is intentional, because we do not create possible duplicates, because a person exists as a record EITHER in system A OR system B.
Unidirectional synchronization
We would get the following in system B – with unidirectional synchronization from A -> B:
| ID | Name | |
|---|---|---|
| A | mary@info.com | Mary |
| B | john@info.com | John |
| C | jane@info.com | Jane |
| D | thomas@info.com | Thomas |
We create the records from system A in system B, because there is no relation yet. Mary with ID “A” from system B will not get a relation in the relation store, because we synchronize from A to B unidirectionally. The following relation table is created:
| ID System A | ID System B |
|---|---|
| 1 | B |
| 2 | C |
| 3 | D |
Bidirectional synchronization
We create the records from system A in system B, since no relations exist yet. The same applies in the opposite direction. We create the records (in our example only one record) from system B in system A, because we configure a bidirectional synchronization. The following relation table is created:
| ID System A | ID System B |
|---|---|
| 1 | B |
| 2 | C |
| 3 | D |
| 4 | A |
Data in System A looks like this:
| ID | Name | |
|---|---|---|
| 1 | john@info.com | John |
| 2 | jane@info.com | Jane |
| 3 | thomas@info.com | Thomas |
| 4 | mary@info.com | Mary |
System B looks exactly the same as in the unidirectional synchronization.
Case 2: Records referring to the same object in the real world, possible before first synchronization in both systems
We synchronize contact data, uni- or bidirectionally does not matter, from system A to system B. An important assumption here is that both systems can have data records that refer to the same object in the real world, in our case the same person. In other words, it could happen that a person is stored as a record in both systems.
We assume that the unique identifier in the systems is the “ID” field, not the email address! This means that during synchronization we define the “ID” field as the identifier for both system A and system B. The initial situation in the systems is as follows:
System A
| ID | Name | |
|---|---|---|
| 1 | john@info.com | John |
| 2 | jane@info.com | Jane |
| 3 | thomas@info.com | Thomas |
System B
| ID | Name | |
|---|---|---|
| A | john@info.com | John |
| B | jane@info.com | Jane |
| C | mary@info.com | Mary |
Important: If we now simply synchronize based on the ID, we create duplicates!
We would get the following data in system B – with unidirectional synchronization from A -> B:
| ID | Name | |
|---|---|---|
| A | john@info.com | John |
| B | jane@info.com | Jane |
| C | mary@info.com | Mary |
| D | john@info.com | John |
| E | jane@info.com | Jane |
| F | thomas@info.com | Thomas |
We create duplicates for John and Jane because we have chosen the criterion for unique identification “ID”. Since the field “Mail” will probably not be unique in the systems, we cannot select it as identifier. The duplicates occur because there is no information yet stored in the HubEngine about which records from both systems belong together (this will be stored as a relation in the Relation Store).
How do we solve this problem? Before the first synchronization, relations are uploaded to the Relation Store via CSV file. The file must be created manually. The relations must have a 1:1 relationship. We upload the following table:
| ID System A | ID System B |
|---|---|
| 1 | A |
| 2 | B |
Now, when we synchronize, no duplicates are created because the HubEngine can look up the record mapping in the Relation Store before synchronizing. We get properly in system B:
| ID | Name | |
|---|---|---|
| A | john@info.com | John |
| B | jane@info.com | Jane |
| C | mary@info.com | Mary |
| D | thomas@info.com | Thomas |
Relation Store deactivated
There are cases when it makes sense to disable the Relation Store. The most common example is the transfer of event logs or transaction data. This means that data is only transferred once, since it does not change after it has been created, such as:
- Opening an e-mail
- Filling out a form
- Clicking a link
To illustrate, let’s take the following example: opening an email. We transfer the data from system A (“Tracking_A”) to system B. We transfer to a custom module (“Tracking_B”) in system B. We cannot transfer to the Contacts module because 1:n relations must exist between Contacts and the Custom module. A contact can be linked to n events, as opening an email.
We extend case 1 with the two upper modules: Tracking_A and Tracking_B. Tracking_A contains the following data, while Tracking_B is still an empty module:
System A - Tracking_A
| Event_ID_A | Contact_ID | Mail_ID | Date | Creation_Date |
|---|---|---|---|---|
| E_A1 | 1 | M1 | 05.03.2022 09:19:14 | 05.03.2022 09:21:37 |
| E_A2 | 2 | M1 | 05.03.2022 16:42:49 | 05.03.2022 16:44:26 |
| E_A3 | 3 | M2 | 07.03.2022 19:54:35 | 07.03.2022 19:55:59 |
Now we transfer unidirectionally Tracking_A -> Tracking_B. Accordingly, Tracking_B looks almost identical. The only difference is the ID assigned by the system when creating a record, i.e. in system A Event_ID_A and in system B Event_ID_B.
System B - Tracking_B
| Event_ID_B | Contact_ID | Mail_ID | Date | Creation_Date |
|---|---|---|---|---|
| E_B1 | 1 | M1 | 05.03.2022 09:19:14 | 05.03.2022 20:00:56 |
| E_B2 | 2 | M1 | 05.03.2022 16:42:49 | 05.03.2022 20:00:57 |
| E_B3 | 3 | M2 | 07.03.2022 19:54:35 | 07.03.2022 20:00:45 |
We recall that the contacts from system A and B are already synchronized unidirectionally (case 1). We add the ID_A field to the contact module in system B, which contains the ID from system A:
System B - Contacts
| ID | Name | ID_A | |
|---|---|---|---|
| A | mary@info.com | Mary | 4 |
| B | john@info.com | John | 1 |
| C | jane@info.com | Jane | 2 |
| D | thomas@info.com | Thomas | 3 |
Now a relation can be created in System B between the Contacts and Tracking_B modules using the Contact_ID and ID_A.
When is the Relation Store not required?
So much for the basic idea of the depicted data synchronization and transfer. We transfer unidirectionally from the Tracking_A module. The IDs, which are defined in the HubEngine as identifiers for the synchronization, are in this case the fields Event_ID_A and Event_ID_B. We transfer the record, an event, only once, since the record will definitely not change again. Accordingly, the HubEngine does not have to ask again whether a record has changed and keep it synchronized.
In terms of chronological sequence, The HubEngine works in a simplified manner as follows. The plan in this example is triggered every day at 8 pm. The change date is indicated by the Creation_Date field.
- Execution of integration plan on 05.03.2022 20:00:00. Records with change date > 04.03.2022 20:00:00 (time of last plan execution) & change date < 05.03.2022 20:00:00 (current date) are queried. Thereby we get the records E_A1 and E_A2. These are transferred to system B and newly created there.
| Event_ID_A | Contact_ID | Mail_ID | Date | Creation_Date |
|---|---|---|---|---|
| E_A1 | 1 | M1 | 05.03.2022 09:19:14 | 05.03.2022 09:21:37 |
| E_A2 | 2 | M1 | 05.03.2022 16:42:49 | 05.03.2022 16:44:26 |
- Execution of integration plan on 03/06/2022 20:00:00. Records with change date > 03/05/2022 20:00:00 (time of last plan execution) & change date < 03/06/2022 20:00:00 (current date) are queried. In doing so, we do not receive any records.
- Execution of integration plan on 03/07/2022 20:00:00. Records with change date > 03/06/2022 20:00:00 (time of last plan execution) & change date < 03/07/2022 20:00:00 (current date) are queried. Thereby we get the data record E_A3. This is transferred to system B and newly created there.
| Event_ID_A | Contact_ID | Mail_ID | Date | Creation_Date |
|---|---|---|---|---|
| E_A3 | 3 | M2 | 07.03.2022 19:54:35 | 07.03.2022 19:55:59 |
Now it becomes clear why no relations are needed. Since the change date (Creation_Date field) in module Tracking_A is guaranteed not to change in system A (the event is completed), a record transferred once cannot be transferred and created again – creating duplicates is ruled out by the given data structure. Therefore, we do not need any link to the records in the Tracking_B module, i.e. no relations. The HubEngine plan is configured using the “create only” option.