You can configure the mapping of the fields in the HubEngine under the Connection tab for the respective synchronization direction. In the mapping, you define which fields of the respective systems are to be synchronized with each other. In the example shown, SAP is integrated with HubSpot. In this case, the fields are called the same on both sides (since demo instances), but this will likely differ in reality.

If you click on the “Edit” button, you can edit the entire connection. This includes:
- Mapping
- Actions
- Conditions
- Advanced Options
Input in this synchronization refers to the SAP system, while output refers to HubSpot. Now if we were to model the other direction (i.e. HubSpot -> SAP), it would be swapped. Still, input system would be listed on the left and output system on the right.
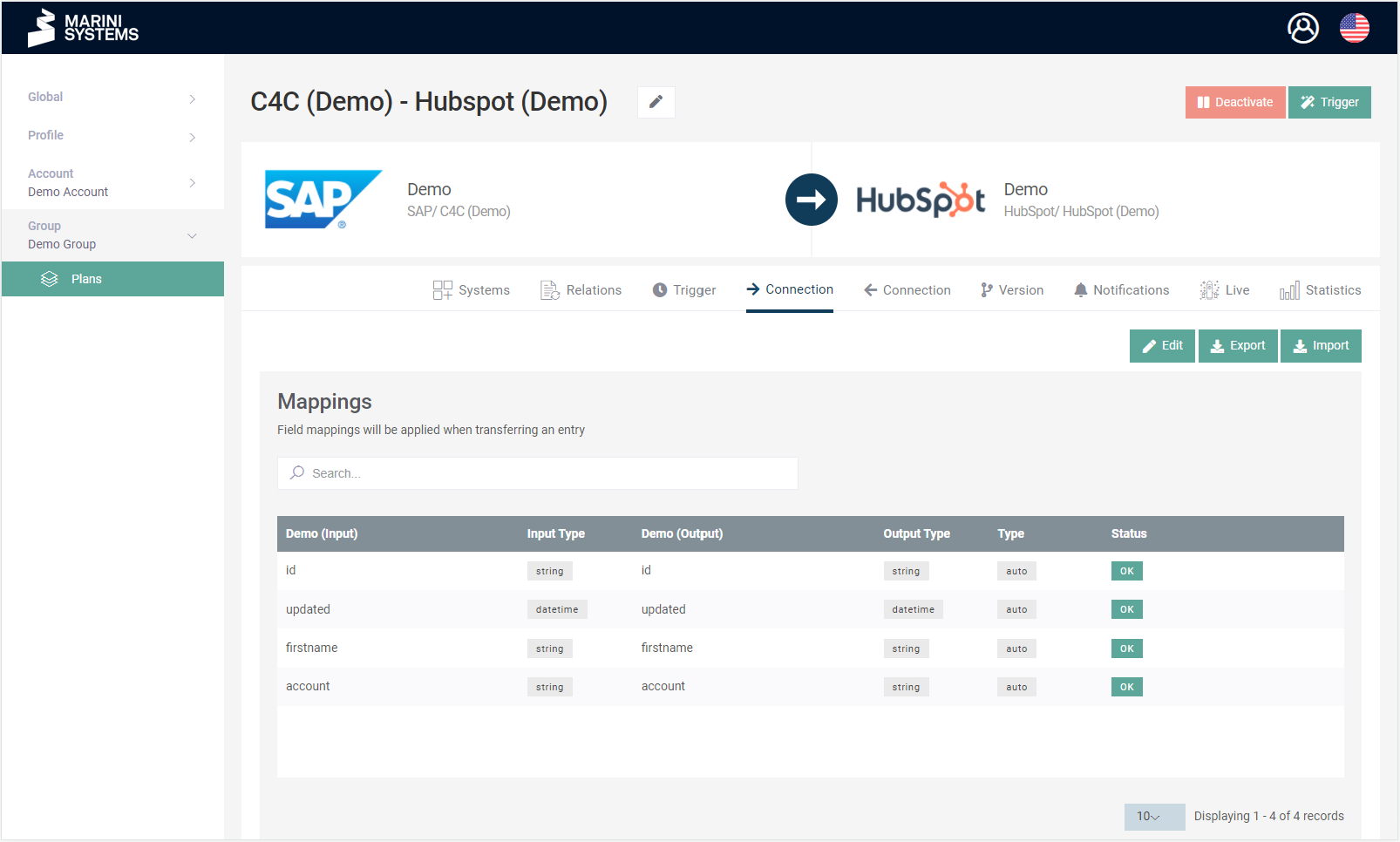
You can select the fields for mapping via a drop-down menu. The fields were retrieved from the systems either at the beginning of the plan setup by automatically running the “Test and Fetch Fields” function or manually at a later time and were stored in the HubEngine. If new fields are added in the connected systems, “Test and Fetch Fields” must be executed again. The function is available under the “System” tab.
A type can be selected for each field. The following types are available:
- auto
- int (integer)
- string
- bool (boolean)
- date / datetime
- regex
- mapping
- relation lookup
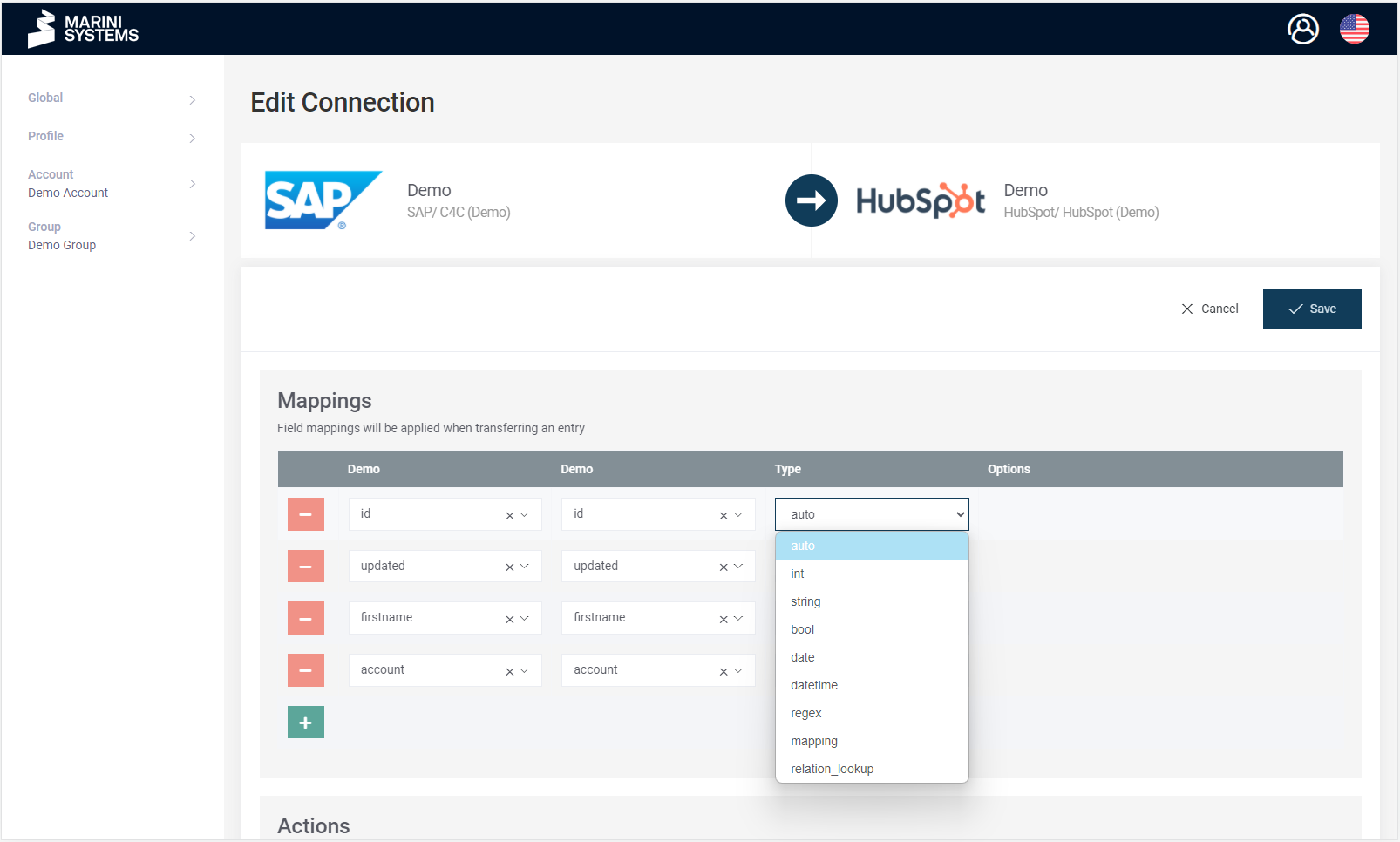
In most cases the option “auto” is sufficient. The options for “int”, “string”, “bool”, “date”, “datetime” will result in the adapter transferring the data to the target system in this database field format (i.e. enforcing format). The options should only be selected if the integrity of the formats can be ensured. Otherwise, the “auto” option is recommended, as it works most robustly.
Regex
Regex is only useful when reading from a string field. Regex can be used to manipulate the string. So certain characters can be extracted from a string. So a transformation of text can take place before the data is transferred.
Transformation/Replace
The Transformation/Replace within Regex uses the following syntax:
Form 1: t/[REGEXP]/[REPLACEMENT]
[REGEXP]is a regular expression with one or more capturing groups.[REPLACEMENT]is the replacement string that uses back references prefixed with$starting with 1.
If the input string does not match, the string remains unchanged.
Form 2: t/[REGEXP]/[REPLACEMENT]/[DEFAULT]
[DEFAULT]is a plain string used when the input string does not match.[DEFAULT]can be an empty string.
Examples:
t/(.*)-(.*)/$2-$1–hello-world->world-hello,not_matching->not_matchingt/(.*)-(.*)/$2-$1/–hello-world->world-hello,not_matching-> “t/(.*)-(.*)/$2-$1/missing-value–hello-world->world-hello,not_matching->missing-value
Relation Lookup
With the Relation Lookup you can perform a lookup based on other relations. How exactly this works, we explain in a separate article.
Mapping of field options
Under this option you can specify actions and mappings. The simplest example is when you only specify a mapping of values. A common example would be the following mapping:
- From “Mrs” to “Frau”
- From “Mr” to “Herr”
With this you could, if the salutation is available in English, translate it into German.
But you also have more complex possibilities with the actions.
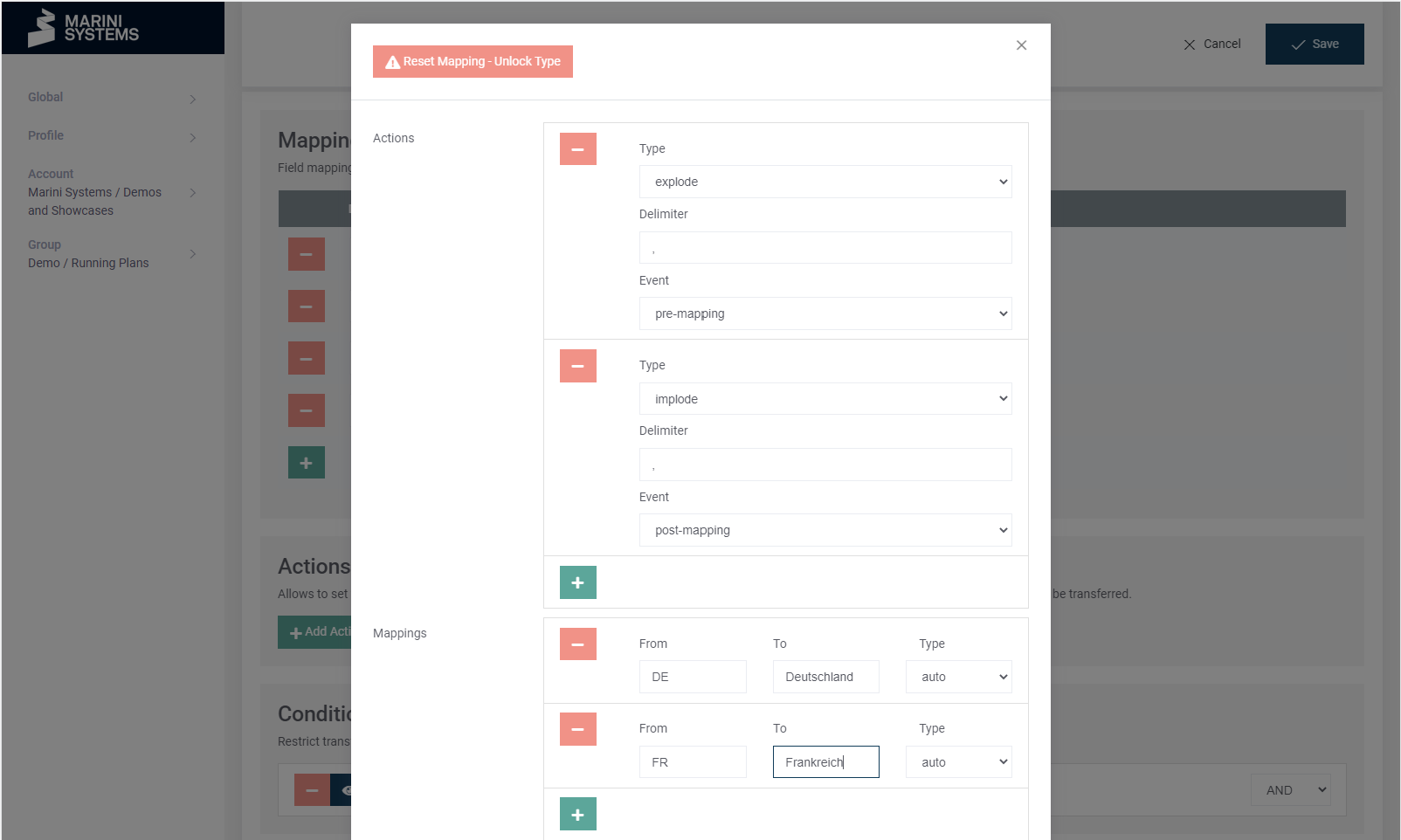
In the above example, we expect a field that could contain the following:
- “DE”
- “FR”
- “DE,FR”
- “FR,DE”
By configuring above, we transform it accordingly to:
- “Deutschland”
- “Frankreich”
- “Deutschland,Frankreich”
- “Frankreich,Deutschland”
This makes the functionality clear. I can edit a list of values by splitting them first, then mapping them, and then concatenating them again.