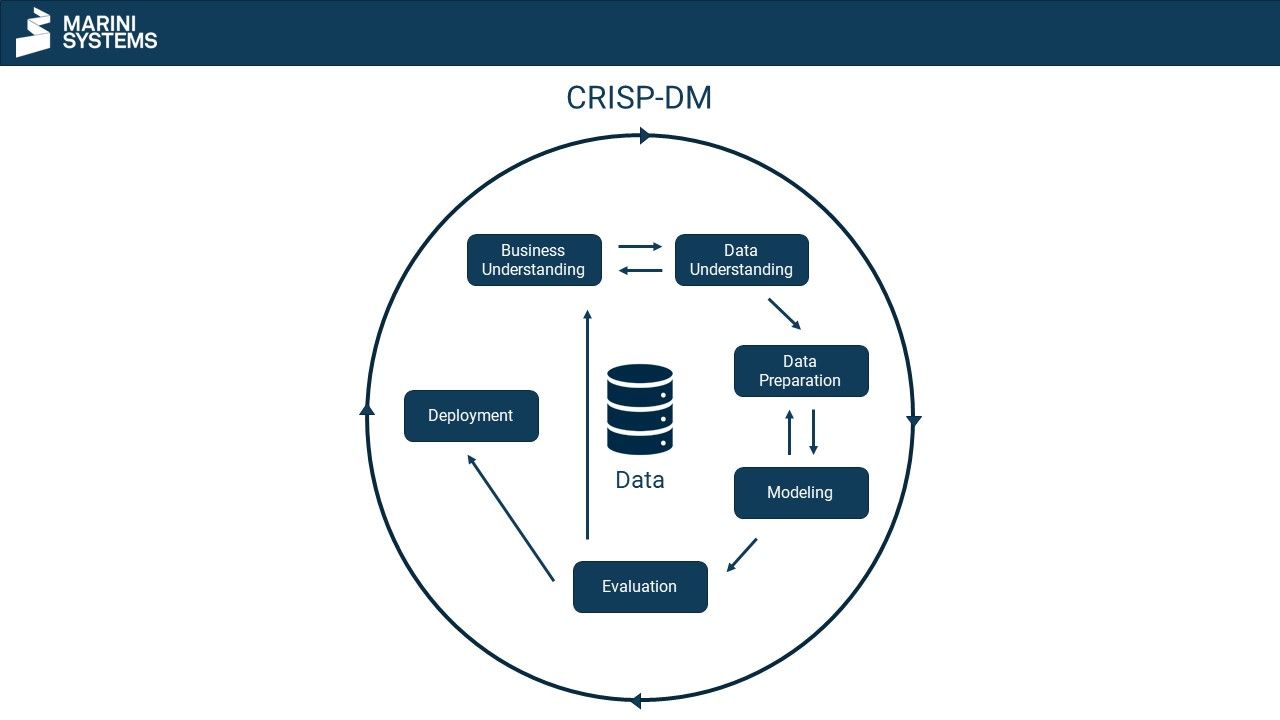
CRISP-DM stands for cross-industry standard process for data mining and describes a widely accepted standard for data mining processes. CRISP-DM divides the data mining process into 6 phases:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
Business Understanding
In Business Understanding, concrete questions and requirements are derived from corporate goals and the corporate strategy. From these, a rough framework can be determined in which the data mining should take place.
Data Understanding
In second place is the understanding of the data. This phase includes data collection and data exploration. Collecting data can, for example, consist of compiling it from various sources such as databases or spreadsheets. The data does not necessarily have to be available in a structured form. In data exploration, the data is examined and explored without the aid of a model. Results may concern the data quality, quantity, structure, data format, characteristics or initial relationships within the data. Depending on the results in the Data Understanding, the system switches back to the Business Understanding in order to redefine the goals, requirements and framework with the help of the findings.
Data Preparation
Data preparation puts the data into the format required for the model, often a table consisting of examples (rows/observations) and features (columns/predictors). The data preparation also includes the split into training and test data set.
Modeling
Then the model is trained (also “fitted”). Here, the algorithm determines the parameters of the respective model given the input data from the training data. It is quite common to train several models like logistic regression, random forest, decision trees and/or gradient boosting.
Evaluation
In model evaluation, the estimated models are evaluated according to their model performance. This is done with unseen data, usually those of the test data, which were not used for model training. If the model performance is insufficient, it may be necessary to start again with data collection. If necessary, the data may have to be enriched with additional data. It would also be conceivable to choose a different algorithm for the model training step. If the results of the evaluation are insufficient, the process restarts with the Business Understanding. The iteration continues until the evaluation is completed positively.
Deployment
The deployment phase describes a productive instance, i.e. the final implementation and application of the data mining and/ or machine learning model.