While monitoring the DataEngine instances, we noticed unusually high disk and CPU activity. Our investigation then revealed that improperly configured workflows were the cause.
Here is the initial situation we found:
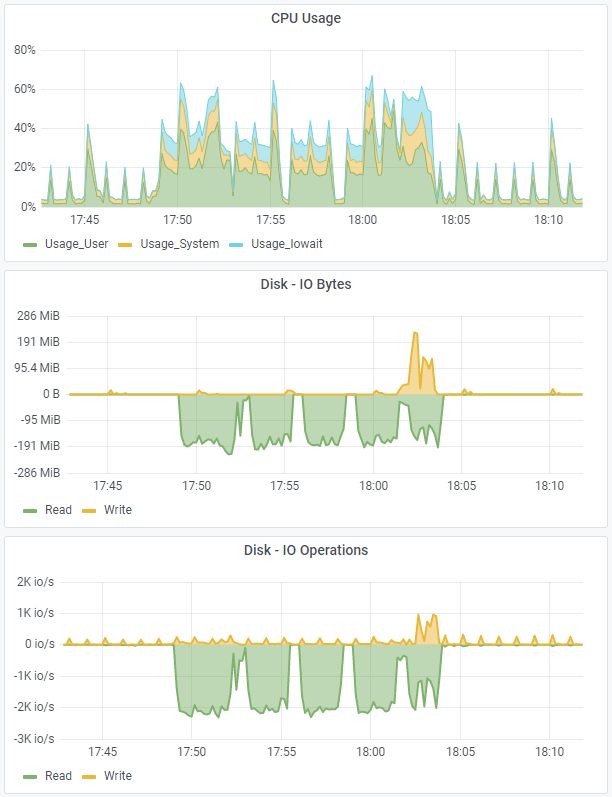
The upper diagram shows a CPU utilization of around 40%, combined with high read activities to the hard disks (middle and lower diagram – green line).
This workflow was responsible for this:

What we see here is a workflow that runs not only in the scheduler (i.e. every minute), but also when saving. (1) Furthermore, we have not set any conditions, so that this workflow is applied to all records in the CDP Contact module every minute. (2) What is not visible here is that the action updates the record itself, which in turn triggers an “on-save” event and thus this workflow again. (3)
So a recursive loop was built, which only exits when there is a saving error. Changing the same record, without a corresponding condition and calling the same workflow at the same time is deadly. Here, the instance was barely usable during execution.
Conclusion:
If you want to repeatedly update the same records via a workflow, you have to set appropriate conditions that prevent you from setting up recursive loops here. If several actions are executed one after the other (with a change of the calling record), the condition for the execution of the workflow should be set right at the beginning. Then a new call is prevented.


