Die Verfahren Random Forest, Logistische Regression oder Gradient Boosting lassen sich im Machine Learning in die Kategorie des Überwachten Lernens (engl. Supervised Learning) einordnen. Überwachtes Lernen ist dadurch gekennzeichnet, dass die Werte der Zielvariable im Vorherein bekannt sind. Beispielsweise ob ein Kunde gekauft hat oder nicht. Die Werte der Zielvariable werden nicht nur zur Modellbildung, sondern ebenso zur Modellevaluation und -selektion benötigt.
Wie gut ist mein Modell?
Liegt ein Datensatz mit n Beobachtungen vor, wird dieser zufällig in Trainings- und Testdatensatz geteilt (bspw. 70/30). Auf 70% der Daten wird das Modell „trainiert“. Die verbleibenden 30% der Daten werden verwendet, um die Performance des Modells zu validieren. Bestenfalls ist ein vollständig differenter Datensatz (erhoben zu einem anderen Zeitpunkt, an einem anderen Ort, mit anderen Personen etc.) vorhanden. Dieser kann die Modellperformance auf unabhängigen Daten ermitteln, da die Wahrscheinlichkeit groß ist, dass der Trainingsdatensatz und Testdatensatz stark korreliert sind. Dies hat zur Folge, dass die Modellperformance überschätzt wird.
Aus Modellevaluation folgt Modellselektion
Die Modellselektion aus mehreren Modellen erfolgt auf Basis der Modellevaluation auf dem Testdatensatz. Dieser enthält für das Modell „ungesehene“ Daten. Zur Evaluation von Modellen bei Klassifizierungsproblemen existieren verschiedene Maßzahlen. Eine häufig verwendete Maßzahl leitet sich aus der resultierenden Kontingenztabelle oder Konfusionsmatrix ab. Die simpelste Klassifizierungsfrage unterscheidet zwei Klassen. Im Folgenden beschreiben die Klassen entweder einen negativen (Label 0) oder positiven (Label 1) Outcome.
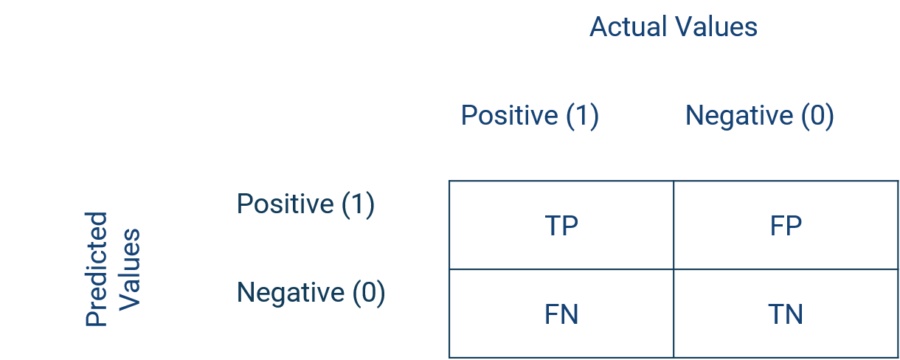
Konfusionsmatrix
Werden Beobachtungen, deren Werte der Zielvariable bekannt sind, durch ein Modell klassifiziert, ergeben sich 4 Zellen einer Kontingenztabelle. Die Beobachtungen, welche als positiv klassifiziert werden und positiv sind, nennt man True Positives (TP).Gleichermaßen gilt: Die Beobachtungen, welche negativ klassifiziert sind und solche sind, werden True Negatives (TN) genannt. Die Beobachtungen, welche als negativ klassifiziert werden, jedoch positiv sind, nennt man False Negatives (FN). Sind die Beobachtungen hingegen als positiv klassifiziert, aber tatsächlich negativ, so nennt man diese False Positives (FP).
Performance-Metriken
Eine Maßzahl, welche sich aus der Kontingenztabelle ableitet, ist die Genauigkeit (Gleichung 1). Sie gibt an, wie viel Prozent der Beobachtungen richtig klassifiziert wurden. Die Spezifität (Gleichung 2) beschreibt, wie viel Prozent korrekt positiv klassifiziert wurden im Verhältnis zu allen positiven Beobachtungen. Gleicher Logik folgend, gibt die Sensitivität an, wie viel Prozent korrekt negativ klassifiziert wurden gemessen an allen negativen Beobachtungen.
- Gleichung 1: Genauigkeit = (TP+TN) / (TP+FP+TN+FN)
- Gleichung 2: Spezifität = TN / (FP+TN)
- Gleichung 3: Sensitivität = TP / (FN+TP)
Aus der Konfusionsmatrix das Modell selektieren
Nun können Modelle mit verschiedenen Modellspezifikationen auf dem Trainingsdatensatz trainiert und auf dem Testdatensatz evaluiert werden. Evaluationsmaße können beispielsweise Genauigkeit, Spezifität und/oder Sensitivität (weitere Performance-Metriken)sein. So kann beispielsweise das Modell, welches die höchste Genauigkeit aufweist, als finales Modell gewählt werden. Derart ist es möglich, beliebig viele Modellspezifikationen oder Verfahren wie Random Forest oder Gradient Boosting gegeneinander zu testen und zu evaluieren. Natürlich immer limitiert durch Computation Power und Zeit.
Das Problem der unbalancierten Klassen
Eine Einschränkung erfährt die Genauigkeit dann, wenn die Klassen ungleich verteilt sind. Sind beispielsweise 90% der Beobachtungen positiv, kann ein Algorithmus dazu tendieren fast alle Beobachtungen als positiv einzustufen, was zu einer hohen Anzahl False Positives führt. Dies resultiert in einer hohen Spezifität, jedoch geringen Sensitivität. Um dem Rechnung zu tragen, kann die sogenannte Receiver Operating Curve ermittelt werden, wobei auf der X-Achse 1-Spezifität und auf der Y-Achse die Sensitivität abgetragen werden.
Area Under Curve
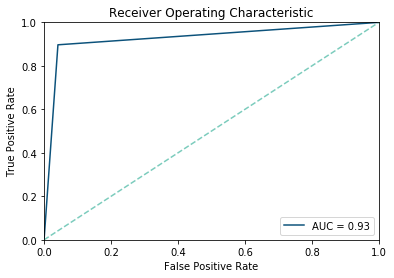
Damit stellt sie den Zusammenhang zwischen Gewinnen (True Positives) und Kosten (False Positives) dar. Abgeleitet daraus ergibt sich die Maßzahl Area Under the Curve (AUC). Der AUC Wert beschreibt den Anteil unter der ROC Curve, welcher maximal 1 und minimal 0 sein kann. Da Random Guessing in etwa der Hälfte der Fälle (bei balanciertem Datensatz) richtig klassifiziert, sollte jedes Modell einen AUC Wert von höher 0,5 aufweisen. Nun kann der AUC Wert zur Modellselektion verwendet werden.
Mehr Details findet Ihr hier.
Du suchst nach einem hands-on Tutorial in Python, wie du deine Modelle evaluieren kannst? Dann schau auf TowardsDataScience vorbei!
Weiterführende Ressourcen zu Machine Learning
Datenintegration
Wie Machine Learning von Datenintegration profitiert
Die Kausalkette „Datenintegration-Datenqualität-Modellperformance“ beschreibt die Notwendigkeit von effektiver Datenintegration für einfacher und schneller umsetzbares sowie erfolgreicheres Machine Learning. Kurzum: aus guter Datenintegration folgt bessere Vorhersagekraft der Machine Learning Modelle wegen höherer Datenqualität.
Betriebswirtschaftlich liegen sowohl kostensenkende als auch umsatzsteigernde Einflüsse vor. Kostensenkend ist die Entwicklung der Modelle (weniger Custom Code, damit weniger Wartung etc.). Umsatzsteigernd ist die bessere Vorhersagekraft der Modelle, was präziseres Targeting, Cross- und Upselling und ein genaueres Bewerten von Leads und Opportunities betrifft – sowohl im B2B- als auch im B2C-Bereich. Hier findest du einen detaillierten Artikel zu dem Thema:
Plattform
Wie du Machine Learning mit der Integration Platform verwendest
Du kannst die Daten deiner zentralen Marini Integration Platform externen Machine Learning Services und Applikationen zur Verfügung stellen. Die Anbindung funktioniert nahtlos durch die HubEngine oder direkten Zugang zur Plattform, abhängig von den Anforderungen des Drittanbieters. Ein Anbieter für Standardanwendungen des Machine Learnings im Vertrieb ist z.B. Omikron. Du kannst aber auch Standardanwendungen auf AWS oder in der Google Cloud nutzen. Eine Anbindung an deine eigenen Server ist ebenso problemlos möglich, wenn du dort deine eigenen Modelle programmieren möchtest.
Wenn du Unterstützung dabei brauchst, wie du Machine Learning Modelle in deine Plattform einbinden kannst, dann kontaktiere unseren Vertrieb. Wir helfen dir gerne weiter!
Anwendungsbeispiele
Häufige Anwendungsszenarien von Machine Learning im Vertrieb
Machine Learning kann auf vielfältige Weise den Vertrieb unterstützen. Es können zum Beispiel Abschlusswahrscheinlichkeiten berechnet, Cross- und Up-Selling-Potenziale geschätzt oder Empfehlungen vorhergesagt werden. Wichtig dabei ist, dass der Vertriebler unterstützt wird und eine weitere Entscheidungshilfe erhält, anhand derer er sich besser auf seine eigentliche Tätigkeit, nämlich das Verkaufen, konzentrieren kann. So kann der Vertriebler zum Beispiel schneller erkennen, welche Leads, Opportunities oder Kunden am vielversprechendsten momentan sind und diese kontaktieren. Es bleibt jedoch klar, dass der Vertriebler die letztendliche Entscheidung trifft und durch das Machine Learning letztlich nur Erleichterungen erfährt. Schlussendlich verkauft kein Modell, sondern immer noch der Mensch.
Hier findest du eine kurze Einführung in das Thema Machine Learning und die häufigsten Anwendungsmöglichkeiten im Vertrieb.