Was genau ist ETL?
ETL steht für Extract, Transform und Load. Im Kern werden Daten aus einer oder mehreren Datenquellen extrahiert, um sie dann aufbereitet in ein Zielsystem zu schreiben. Ein Zielsystem könnte beispielsweise ein Data Warehouse oder ein ERP-System sein. Früher wurden die Daten hauptsächlich in einem Data Warehouse gespeichert. Heute ist es üblich, dass Daten über Systeme hinweg verteilt oder wenig strukturiert in einem Data Lake gespeichert werden.
Das Ziel der Transformation ist es, die Daten aus dem Quellsystem für die weitere Verarbeitung im Zielsystem vorzubereiten. Dabei wird beim ETL eine klar vorgegebene und strukturierte Vorgehensweise verfolgt.
Die Datenbank-Schemata der eingesetzten Systeme unterscheiden sich meist grundlegend. Nicht selten unterscheiden sich auch die Datenstrukturen von Systemen des gleichen Typs. Ein gängiges Beispiel aus dem Vertrieb ist sicher der individuelle Aufbau eines CRM-Systems. Wenn Daten aus dem einen System in ein anderes übertragen werden, ist eine Transformation der Daten und deren Strukturen in der Regel erforderlich.
ETL in Vertrieb und Marketing
Systeme werden zunehmend vernetzt und die gespeicherten Vertiebs- und Marketing-Daten steigen signifikant an. Das Auflösen von Datenbank-Silos und Big Data sind insbesondere im Vertrieb und im Marketing ein wichtiges Thema.
Im Vertrieb werden Systeme integriert, um Prozesse über Systeme hinweg zu modellieren und um sie weitestgehend zu automatisieren. Das ETL-Verfahren muss also in Echtzeit Prozesse integriert sein. Für eben diese Anforderung ist eine ganze Branche entstanden, zu der auch wir uns zählen.
ETL und Dezentrale Plattform
Über iPaaS-Lösungen lässt sich die Integration von Systemen sehr einfach und ohne nennenswerten Programmieraufwand realisieren. Die Daten werden über die APIs des Zielsystems und des Quellsystems bereitgestellt. Über API-Middleware-Applikationen kann der Austausch der Daten zwischen den beiden Systemen verwaltet werden. Die HubEngine ist eine iPaaS-Lösung, die genau diese Aufgabe erledigt, wobei sie über ein No-Coding-Interface flexibel und einfach konfiguriert werden kann.
Manche iPaaS-Lösungen bieten auch Funktionen zur Transformation, beispielsweise das Auflösen von Entitäten. Das Problem hierbei ist es jedoch, dass die Lösungen meist schwierig konfigurierbar und bedienbar sind.
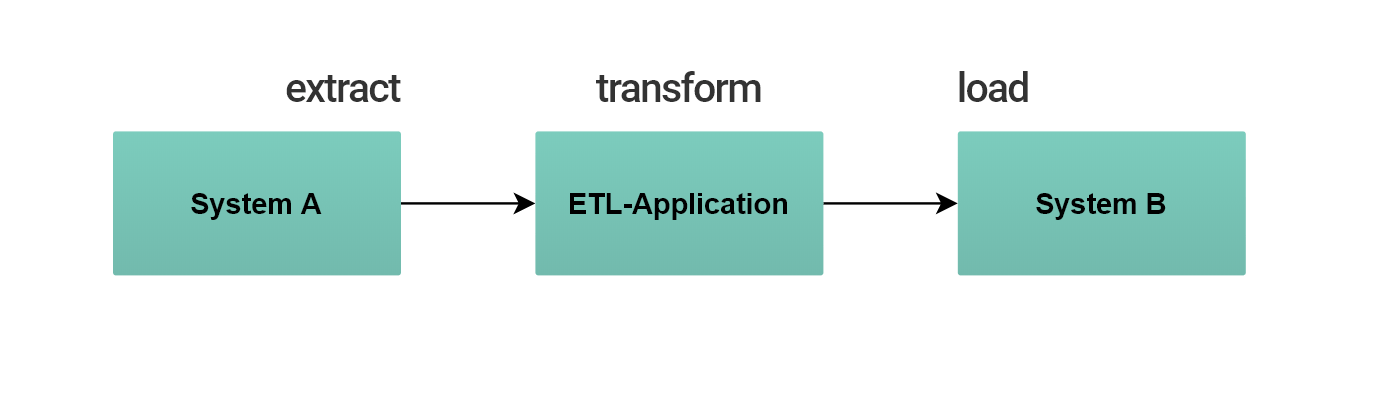
Einfachster Fall einer dezentralen Plattform
Wir nutzen für die Transformation von Datenbank-Schemata gesonderte Applikationen, die wir flexibel und recht einfach zwischen die Systeme schalten. Über die DataEngine bieten wir dafür eine passende Applikation: Die Transformation (ETL) Applikation. Über die DataEngine können beliebige Datenbank-Modelle abgebildet und über Workflows transformiert werden. Wenn also unterschiedliche Datenbank-Schemata synchronisiert oder integriert werden sollen, sieht das Schema einer dezentralen Plattform im einfachsten Fall folgendermaßen aus.

Komplexerer Fall einer dezentralen Plattform
Die Daten können so auch von System B zu System A, also bidirektional, synchronisiert werden. Es ist auch möglich, noch weitere Systeme anzubinden und so alle relevanten Daten über alle eingesetzten Systeme hinweg in Echtzeit zu integrieren. Das folgende Schaubild zeigt eine komplexere dezentrale Plattform. Hier werden zwei Module in System A zu vier Modulen in System B verarbeitet. Selbstverständlich könnte man noch weitere Systeme (C,D,E etc.) inkludieren.

Über die Enterprise Data Platform mit ihren Komponenten HubEngine und DataEngine können beliebig umfangreiche Lösungen aufgebaut werden. In den Lösungen findest du viele Beispiele wie so etwas aussehen könnte.