Entscheidungsbäume modellieren die Beziehung zwischen Features und einer Zielvariable mithilfe der Struktur eines Baumes. Bei Klassifizierungsentscheidungsbäumen ist die Zielvariable eine kategoriale (meist binär) Variable. Ziel ist es, durch die Features die Zugehörigkeit zu einer Klasse vorherzusagen. Durch rekursives Partitionieren (teilen des Datensatzes) anhand der Features entstehen möglichst homogene Gruppen, welche wiederum in weitere möglichst homogene Gruppen unterteilt werden, bis ein Stoppkriterium einsetzt oder die festgelegte Homogenität erreicht ist. Die Unterteilung kann aufgrund verschiedener Maßzahlen erfolgen wie z.B. dem Information Gain oder dem Gini-Index.
Entscheidungsbäume starten mit einem Wurzelknoten, welcher alle Beobachtungen enthält (oberster Knoten in unten dargestelltem Baum). In weiteren Schritten werden die Beobachtungen in binären Splits weiter unterteilt, beispielsweise anhand des Gini-Index. Findet ein Split statt, werden alle verbleibenden Features betrachtet und dasjenige gewählt, das den Datensatz derart optimal teilt, dass möglichst homogene (eng. pure) Gruppen entstehen. Homogen heißt, dass die Gruppe maximal viele Beobachtungen einer Ausprägung der Zielvariable enthält (je mehr, sie enthält desto reiner, engl. pure, ist sie).
Visualisierter Entscheidungsbaum
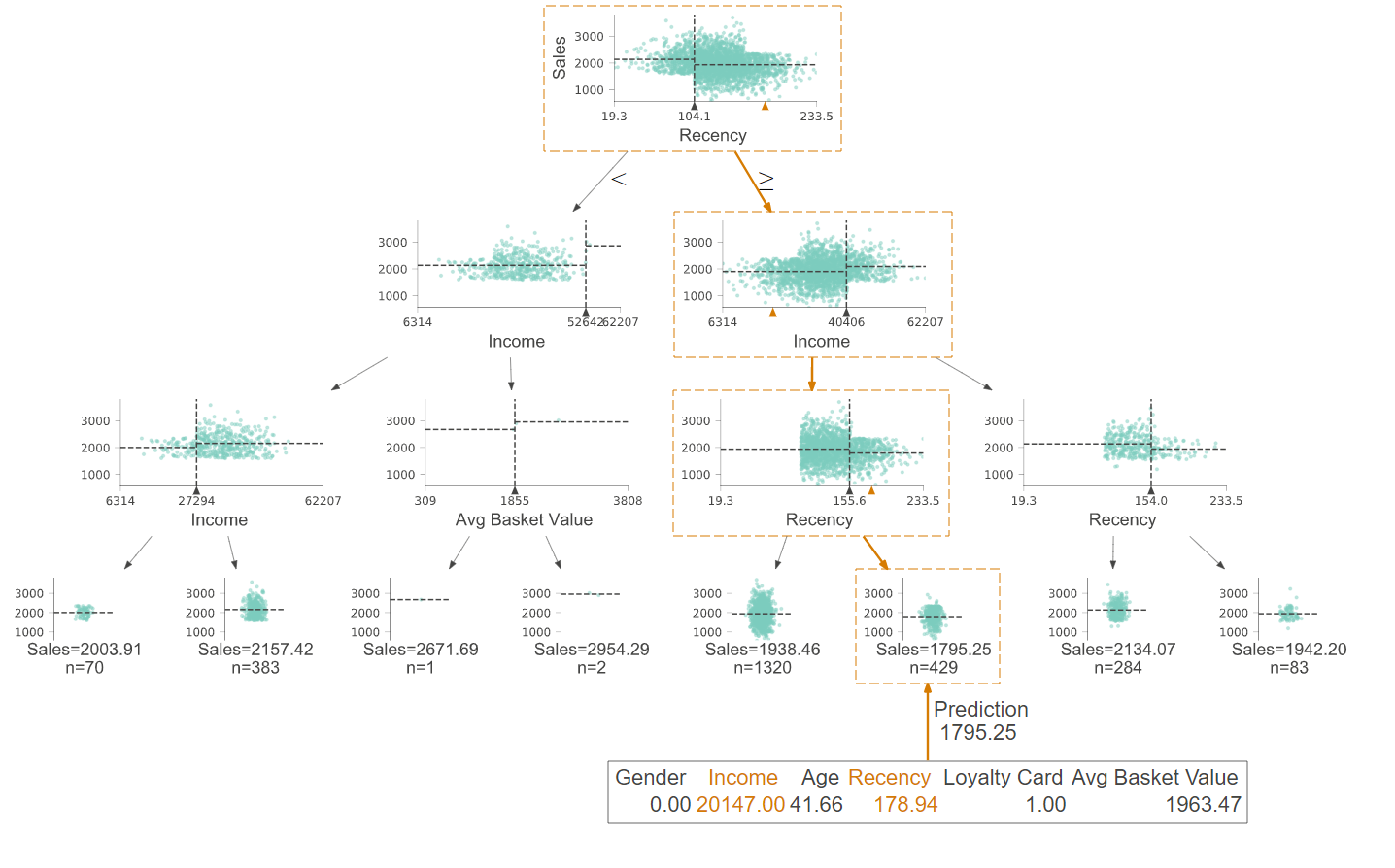
Der obige Entscheidungsbaum bildet keine kategoriale Zielvariable ab, sondern eine kontinuierliche. Dadurch können auch kontinuierliche Variablen, wie beispielsweise Umsatz geschätzt werden.
Code Snippet
from sklearn.tree import DecisionTreeClassifier
from sklearn.externals.six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
clf = DecisionTreeClassifier(max_depth=4, criterion = „gini“)
clf = clf.fit(X_train, y_train)
export_graphviz(clf, out_file=dot_data, filled=True, rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
Weitere Infos zum Coden gibt’s für Python in der Dokumentation von sklearn.
Erläuterung des Entscheidungsbaums
Der visualisierte Entscheidungsbaum stellt einen Regressionsbaum dar, der eine kontinuierliche Zielvariable schätzt. Der erste Split erfolgt am Wurzelknoten. Wenn die „recency “ kleiner als 104.1 ist, wird der linke Zweig gewählt, ansonsten der rechte.
Die untersten Knoten stellen Endknoten dar. Die Größe des Entscheidungsbaums kann durch die Einstellung verschiedener Parameter gesteuert werden. In diesem Fall wurden die Parameter so eingestellt, dass kein großer Entscheidungsbaum wächst (Varianz-Bias-Trade-Off). Wenn eine neue Beobachtung (wie z.B. der orangen Pfad) geschätzt werden soll, wird der Entscheidungsbaum nur von oben nach unten durchlaufen. Dies zeigt eine Stärke von Entscheidungsbäumen: die einfache Interpretation. Außerdem kann auf die Variablenwichtigkeit geschlossen werden. Je weiter oben eine Variable steht, desto wichtiger ist sie für die Vorhersage.
Vor- und Nachteile
Vorteile
- Einfach zu interpretieren – dank Visualisierung
- Verwendung in vielerlei Business-Kontexten
- Spezifisch – bedienen ein bestimmtes Problem: Ergänzen von Kosten- oder Profitfunktionen möglich
- White-Box-Model
Nachteile
- Instabilität: Kleine Änderungen des Datensatzes können zu einem komplett neuen Baum führen
- Overfitting: Bäume können groß und unübersichtlich werden
- Verschiedene Split-Kriterien ergeben verschiedene Bäume
Weiterführende Ressourcen zu Machine Learning
Datenintegration
Wie Machine Learning von Datenintegration profitiert
Die Kausalkette „Datenintegration-Datenqualität-Modellperformance“ beschreibt die Notwendigkeit von effektiver Datenintegration für einfacher und schneller umsetzbares sowie erfolgreicheres Machine Learning. Kurzum: aus guter Datenintegration folgt bessere Vorhersagekraft der Machine Learning Modelle wegen höherer Datenqualität.
Betriebswirtschaftlich liegen sowohl kostensenkende als auch umsatzsteigernde Einflüsse vor. Kostensenkend ist die Entwicklung der Modelle (weniger Custom Code, damit weniger Wartung etc.). Umsatzsteigernd ist die bessere Vorhersagekraft der Modelle, was präziseres Targeting, Cross- und Upselling und ein genaueres Bewerten von Leads und Opportunities betrifft – sowohl im B2B- als auch im B2C-Bereich. Hier findest du einen detaillierten Artikel zu dem Thema:
Plattform
Wie du Machine Learning mit der Integration Platform verwendest
Du kannst die Daten deiner zentralen Marini Integration Platform externen Machine Learning Services und Applikationen zur Verfügung stellen. Die Anbindung funktioniert nahtlos durch die HubEngine oder direkten Zugang zur Plattform, abhängig von den Anforderungen des Drittanbieters. Ein Anbieter für Standardanwendungen des Machine Learnings im Vertrieb ist z.B. Omikron. Du kannst aber auch Standardanwendungen auf AWS oder in der Google Cloud nutzen. Eine Anbindung an deine eigenen Server ist ebenso problemlos möglich, wenn du dort deine eigenen Modelle programmieren möchtest.
Wenn du Unterstützung dabei brauchst, wie du Machine Learning Modelle in deine Plattform einbinden kannst, dann kontaktiere unseren Vertrieb. Wir helfen dir gerne weiter!
Anwendungsbeispiele
Häufige Anwendungsszenarien von Machine Learning im Vertrieb
Machine Learning kann auf vielfältige Weise den Vertrieb unterstützen. Es können zum Beispiel Abschlusswahrscheinlichkeiten berechnet, Cross- und Up-Selling-Potenziale geschätzt oder Empfehlungen vorhergesagt werden. Wichtig dabei ist, dass der Vertriebler unterstützt wird und eine weitere Entscheidungshilfe erhält, anhand derer er sich besser auf seine eigentliche Tätigkeit, nämlich das Verkaufen, konzentrieren kann. So kann der Vertriebler zum Beispiel schneller erkennen, welche Leads, Opportunities oder Kunden am vielversprechendsten momentan sind und diese kontaktieren. Es bleibt jedoch klar, dass der Vertriebler die letztendliche Entscheidung trifft und durch das Machine Learning letztlich nur Erleichterungen erfährt. Schlussendlich verkauft kein Modell, sondern immer noch der Mensch.
Hier findest du eine kurze Einführung in das Thema Machine Learning und die häufigsten Anwendungsmöglichkeiten im Vertrieb.