Cross-Validation ist ein Verfahren für die Validierung von Modellen aus dem Data Mining- und Machine Learning-Bereich.
Die Daten werden in der Data Preparation nach aktuellen Machine-Learning-Standards vorbereitet (Pre-processing). Normalerweise wird nun der Datensatz einmalig in Trainings- und Testdatensatz geteilt (Split). Auf dem Trainingsdatensatz wird das Modell trainiert und auf dem Testdatensatz mit für das Modell ungesehenen Daten evaluiert. Jedoch kann oftmals ein ungünstiger Split in Trainings- und Testdatensatz das Modell gravierend fehlschätzen. Beispielsweise kann die Verteilung der Zielvariable (Target-Klasse) in beiden Split-Datensätzen ungleich sein oder die Verteilung bestimmter Features sich stark unterscheiden. Bei ausreichend großen Datensätzen ist dies jedoch in der Regel kein Problem. Wann ist der Datensatz jedoch groß genug?
k-fold-Cross-Validation
Bei der k-fold-Cross-Validation wird der Datensatz in k Iterationen in Trainings- und Testdatensatz geteilt. Dementsprechend erhalten wir k Modellevaluierungen. Bei einer 5-fold-Cross-Validation (siehe Bild) wird der Datensatz 5x geteilt. Somit wird bei einer 5-fach-Validierung der Datensatz k = 5x in 1/k = 1/5 = 20% Trainingsdatensatz und 80% Testdatensatz geteilt. Gleichermaßen bei k = 10 in 1/k = 1/10 = 10% Trainingsdatensatz und 90% Testdatensatz usw. Die Teilung erfolgt schematisch nach Index und nicht per Zufall. In der ersten Iteration werden die ersten 1/k % der Daten als Trainingsdatensatz verwendet, bei der zweiten Iteration die nächsten 1/k % der Daten usw. (siehe Bild).
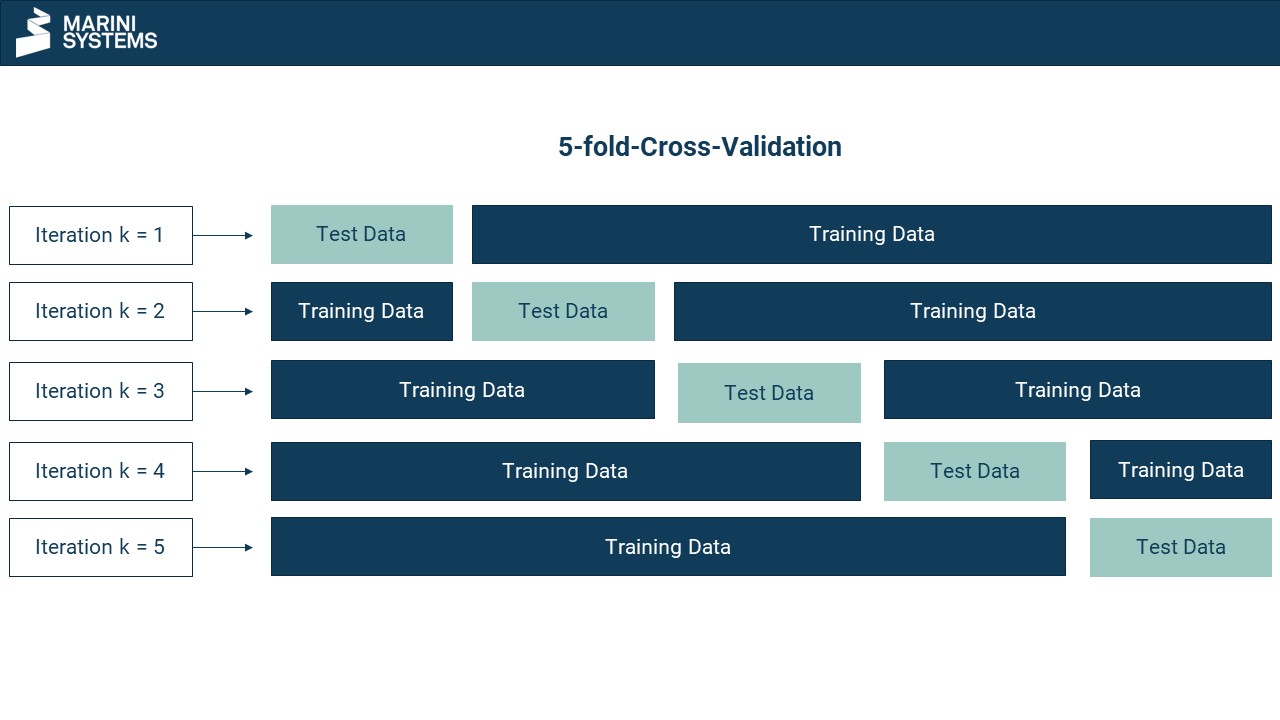
Beispiel
Wir haben einen Datensatz von 1000 Zeilen. Zur Modellevaluation verwenden wir Genauigkeit (True Positive + True Negative / Anzahl der Gesamtzeilen). Im Folgenden ist diese fiktiv und dient der Illustration. Wir wenden eine 5-fold-Cross-Validation an.
- Iteration:
- Testdatensatz: Zeilen 1-200
- Trainingsdatensatz: Zeilen 201-1000
- True Negative: 745
- True Positive: 85
- Genauigkeit: (745+85)/1000 = 83%
- Iteration:
- Testdatensatz: Zeilen 201-400
- Trainingsdatensatz: Zeilen 1-200 & 401-1000
- True Negative: 764
- True Positive: 76
- Genauigkeit: (764+76)/1000 = 84%
- Iteration:
- Testdatensatz: Zeilen 401-600
- Trainingsdatensatz: Zeilen 1-400 & 601-1000
- True Negative: 789
- True Positive: 21
- Genauigkeit: (745+85)/1000 = 80%
- Iteration:
- Testdatensatz: Zeilen 601-800
- Trainingsdatensatz: Zeilen 1-600 & 801-1000
- True Negative: 755
- True Positive: 85
- Genauigkeit: (745+85)/1000 = 84%
- Iteration:
- Testdatensatz: Zeilen 801-1000
- Trainingsdatensatz: Zeilen 1-800
- True Negative: 758
- True Positive: 52
- Genauigkeit: (745+85)/1000 = 81%
Damit erhalten wir eine durchschnittliche Genauigkeit von (83%+84%+80%+84%+81%)/5 = 82,4%.
Erhielten wir nun in einem zufälligen Split eine Genauigkeit von 89%, deutet dies auf Overfitting und einen zufällig ungünstigen Split von Trainings- und Testdatensatz hin.
Wann ist Cross-Validation empfehlenswert?
Vorteile von k-fold-Cross-Validation auf einen Blick
- Identifizierung von Overfitting
- Testen der Robustheit des Modells
- Aussagekräftige Modellperformance auf kleinen Datensätzen
- Aussagekräftige Modellperformance auf Datensätzen mit Balance-Problemen
- Einsatz bei Tuning von Modellen
Die letztendlichen Modellparameter werden in einem üblichen Split in Trainings- und Testdatensatz ermittelt.
Du suchst nach einem hands-on Tutorial in Python, wie du Cross-Validation genau um- und einsetzen kannst? Dann schau auf TowardsDataScience vorbei!
Weiterführende Ressourcen zu Machine Learning
Datenintegration
Wie Machine Learning von Datenintegration profitiert
Die Kausalkette „Datenintegration-Datenqualität-Modellperformance“ beschreibt die Notwendigkeit von effektiver Datenintegration für einfacher und schneller umsetzbares sowie erfolgreicheres Machine Learning. Kurzum: aus guter Datenintegration folgt bessere Vorhersagekraft der Machine Learning Modelle wegen höherer Datenqualität.
Betriebswirtschaftlich liegen sowohl kostensenkende als auch umsatzsteigernde Einflüsse vor. Kostensenkend ist die Entwicklung der Modelle (weniger Custom Code, damit weniger Wartung etc.). Umsatzsteigernd ist die bessere Vorhersagekraft der Modelle, was präziseres Targeting, Cross- und Upselling und ein genaueres Bewerten von Leads und Opportunities betrifft – sowohl im B2B- als auch im B2C-Bereich. Hier findest du einen detaillierten Artikel zu dem Thema:
Plattform
Wie du Machine Learning mit der Integration Platform verwendest
Du kannst die Daten deiner zentralen Marini Integration Platform externen Machine Learning Services und Applikationen zur Verfügung stellen. Die Anbindung funktioniert nahtlos durch die HubEngine oder direkten Zugang zur Plattform, abhängig von den Anforderungen des Drittanbieters. Ein Anbieter für Standardanwendungen des Machine Learnings im Vertrieb ist z.B. Omikron. Du kannst aber auch Standardanwendungen auf AWS oder in der Google Cloud nutzen. Eine Anbindung an deine eigenen Server ist ebenso problemlos möglich, wenn du dort deine eigenen Modelle programmieren möchtest.
Wenn du Unterstützung dabei brauchst, wie du Machine Learning Modelle in deine Plattform einbinden kannst, dann kontaktiere unseren Vertrieb. Wir helfen dir gerne weiter!
Anwendungsbeispiele
Häufige Anwendungsszenarien von Machine Learning im Vertrieb
Machine Learning kann auf vielfältige Weise den Vertrieb unterstützen. Es können zum Beispiel Abschlusswahrscheinlichkeiten berechnet, Cross- und Up-Selling-Potenziale geschätzt oder Empfehlungen vorhergesagt werden. Wichtig dabei ist, dass der Vertriebler unterstützt wird und eine weitere Entscheidungshilfe erhält, anhand derer er sich besser auf seine eigentliche Tätigkeit, nämlich das Verkaufen, konzentrieren kann. So kann der Vertriebler zum Beispiel schneller erkennen, welche Leads, Opportunities oder Kunden am vielversprechendsten momentan sind und diese kontaktieren. Es bleibt jedoch klar, dass der Vertriebler die letztendliche Entscheidung trifft und durch das Machine Learning letztlich nur Erleichterungen erfährt. Schlussendlich verkauft kein Modell, sondern immer noch der Mensch.
Hier findest du eine kurze Einführung in das Thema Machine Learning und die häufigsten Anwendungsmöglichkeiten im Vertrieb.