CRISP-DM steht für cross-industry standard process for data mining und beschreibt einen anerkannten Standard für Data Mining-Prozesse. CRISP-DM unterteilt den Data Mining-Prozess in 6 Phasen:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
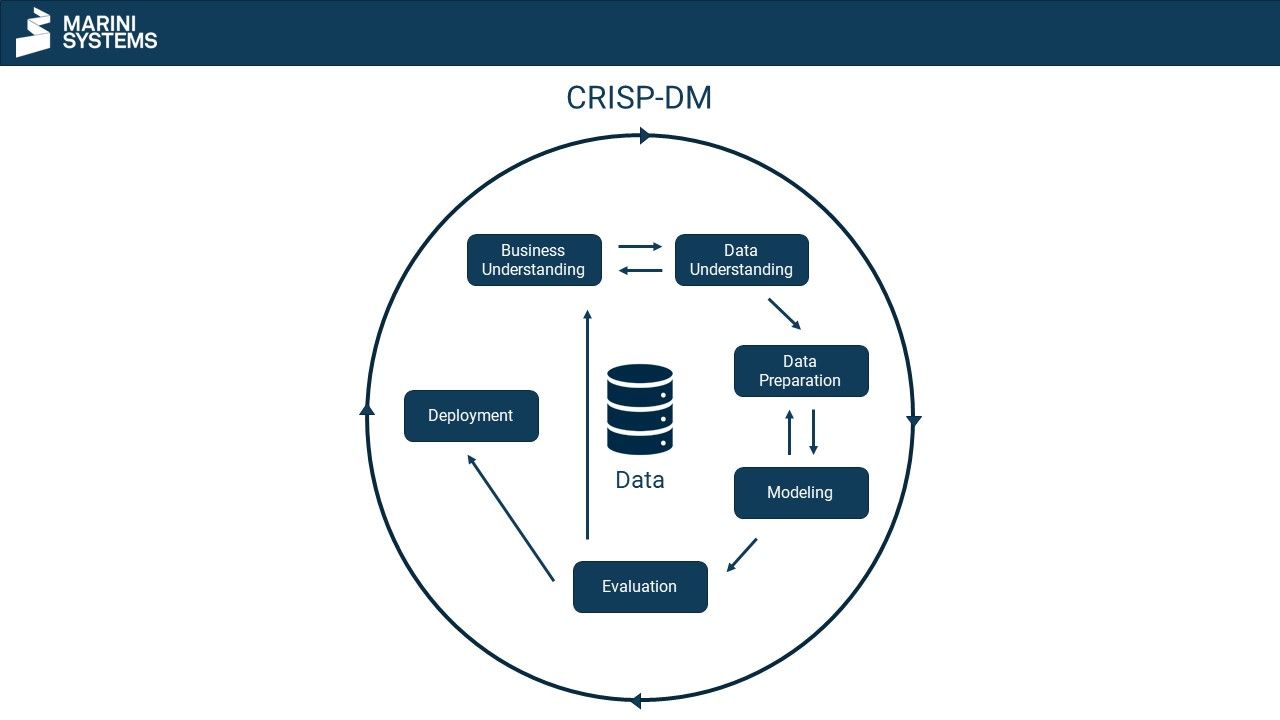
Business Understanding
Im Business Understanding werden aus den festgelegten Unternehmenszielen und der daraus abgeleiteten Unternehmensstrategie konkrete Fragestellungen und Anforderungen definiert. Aus diesen lässt sich ein grober Rahmen ableiten, in welchem das Data Mining stattfinden soll.
Data Understanding
An zweiter Stelle steht das Verstehen der Daten. In diese Phase fallen die Datensammlung und Datenexploration. Das Sammeln der Daten kann beispielsweise aus dem Zusammenstellen aus verschiedenen Quellen wie Datenbanken oder Spreadsheets bestehen. Die Daten müssen noch nicht zwangsläufig strukturiert vorliegen. Bei der Datenexploration werden die Daten ohne Zuhilfenahme eines Modells untersucht und erforscht. Ergebnisse können die Datenqualität, -quantität, -struktur, das Datenformat, Ausprägungen oder erste Zusammenhänge innerhalb der Daten betreffen. Je nach Ergebnissen im Data Understanding wird wieder zurück ins Business Understanding gewechselt, um dort mithilfe der Erkenntnisse die Ziele, Anforderungen und den Rahmen erneut zu definieren.
Data Preparation
Die Datenaufbereitung bringt die Daten in das für das Modell notwendige Format, oftmals eine Tabelle bestehend aus Examples (Zeilen/Beobachtungen) und Features (Spalten/Prädiktoren). Die Datenaufbereitung enthält auch den Split in Trainings- und Testdatensatz.
Modeling
Anschließend wird das Modell trainiert (auch „gefittet“). Hier bestimmt der Algorithmus die Parameter des jeweiligen Modells gegeben der Inputdaten des Trainingsdatensatzes. Es ist durchaus üblich mehrere Modelle wie Logistischer Regression, Random Forest, Entscheidungsbäumen und/oder Gradient Boosting zu trainieren.
Evaluation
In der Evaluationsphase werden die geschätzten Modelle anhand ihrer Modellperformance evaluiert. Dies geschieht mit ungesehenen Daten, nämlich jenen des Testdatensatzes, welche nicht für das Modelltraining verwendet wurden. Ist die Modellperformance unzureichend muss ggf. wieder bei der Datensammlung angesetzt werden. Ggf. muss der Bestand mit weiteren Daten angereichert werden. Ebenso denkbar wäre beim Schritt des Modelltrainings die Wahl eines anderen Verfahrens. Bei unzureichenden Ergebnissen in der Evaluation, startet der Prozess erneut beim Business Understanding. Die Iteration erfolgt, solange bis die Evaluation positiv abgeschlossen werden kann.
Deployment
Die Deployment-Phase beschreibt eine Produktiv-Instanz, also die letztliche Implementierung und Anwendung des Data Mining Modells.